写在开头
- 虽然主要在学习iOS,但是越来越感觉,或许iOS的学习真的不需要去死磕,其他的东西同样需要去多看看。本文主要参考于常用排序算法总结(一)
- 结合了visualgo通过动画来学习,另外,visualgo也可以用来学习数据结构,简直是神器。
- 学习阶段:5.6-5.2X
内部排序
通过一定时间的学习,可以知道内部排序是指待排序列完全存放在内存中所进行的排序过程,适合不太大的元素序列。
排序是计算机程序设计中的一种重要操作,其功能是对一个数据元素集合或序列重新排列成一个按数据元素某个相知有序的序列。排序分为两类:内排序和外排序。
其中快速排序的是目前排序方法中被认为是最好的方法。
内部排序方法:
- 插入排序(直接插入排序);
- 快速排序;
- 选择排序(简单选择排序);
- 归并排序
- 冒泡排序;
- 希尔排序(希尔排序是对直接插入排序方法的改进);
- 堆排序;
排序算法的稳定性(腾讯校招2016笔试题曾考过)
排序算法稳定性的简单形式定义为:如果Ai=Aj,排序前Ai在Aj之前,排序后Ai还在Aj之前,则称这种排序算法是稳定的。通俗地讲就是保证排序前后两个相等的数的相对顺序不变。
对于不稳定的排序算法只要举出一个实例,即可说明它的不稳定性;而对于稳定的排序算法,必须对算法进行分析从而得到稳定的特性。需要注意的是,排序算法是否为稳定的是由具体算法决定的,不稳定的算法在某种条件下可以变为稳定的算法,而稳定的算法在某种条件下也可以变为不稳定的算法。
例如,对于冒泡排序,原本是稳定的排序算法,如果将记录交换的条件改成A[i]>= A[i+1],则两个相等的记录就会交换位置,从而变成不稳定的排序算法。
其次,说一下排序算法稳定性的好处。排序算法如果是稳定的,那么从一个键上排序,然后再从另一个键上排序,第一个键排序的结果可以为第二个键排序所用。基数排序就是这样,先按低位排序,逐次按高位排序,低位排序后元素的顺序在高位也相同时是不会改变的。
冒泡排序
首先是我最先接触的冒泡排序,早在我刚接触C语言的时候就知道了这个排序算法,这个算法的名字由来是因为越大(越小)的元素会经由交换慢慢“浮”到数列的顶端。
冒泡排序算法的运作如下:
|
|
由于它的简洁,冒泡排序通常被用来对于程序设计入门的学生介绍算法的概念。冒泡排序的代码如下:
图解: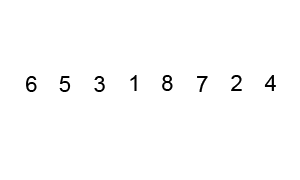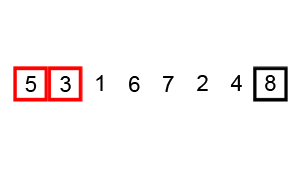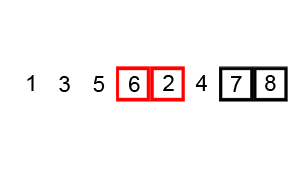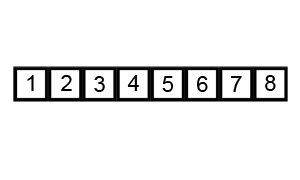
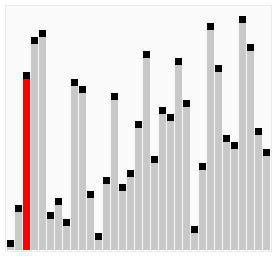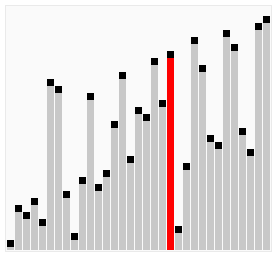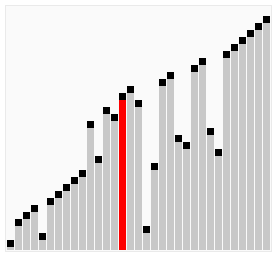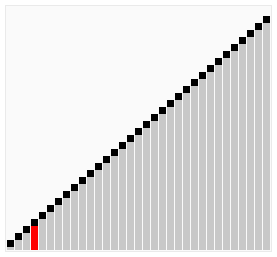
尽管冒泡排序是最容易了解和实现的排序算法之一,但它对于少数元素之外的数列排序是很没有效率的。
冒泡排序的改进:鸡尾酒排序
鸡尾酒排序,也叫定向冒泡排序,是冒泡排序的一种改进。此算法与冒泡排序的不同处在于从低到高然后从高到低,而冒泡排序只会从一个方向去比较序数组里的每个元素。他可以得到比冒泡排序稍微好一点的效能。
鸡尾酒排序的代码如下:
|
|
图解: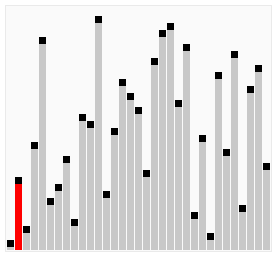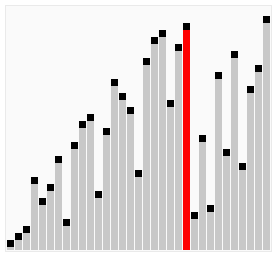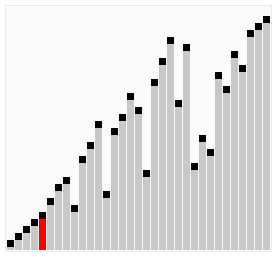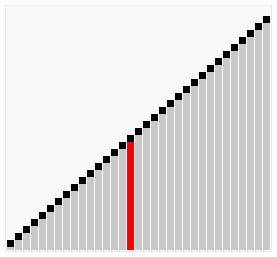
相比于冒泡排序,序列(2,3,4,5,1),鸡尾酒排序只需要访问一次序列就可以完成排序,但如果使用冒泡排序则需要四次。但是在乱数序列的状态下,鸡尾酒排序与冒泡排序的效率都很差劲。
选择排序
选择排序理解起来也很简单。首先在序列中寻找最小(大)元素,放到序列的开头(末尾),再从剩下的序列中寻找最小(大)的元素,放到序列的开头(末尾),直到序列有序。
代码如下:
|
|
图解: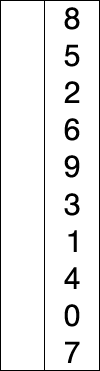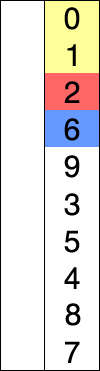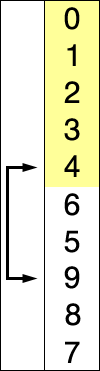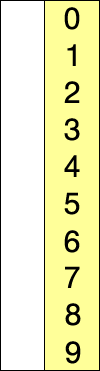
我们很容易就能发现选择排序是不稳定的排序算法,不稳定发生在最小元素与A[i]交换的时刻。
插入排序
插入排序也属于一种很简单的排序。
插入排序算法的运作如下:
|
|
代码如下:
|
|
图解: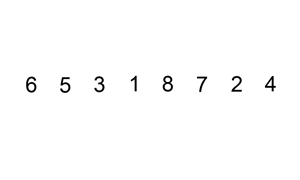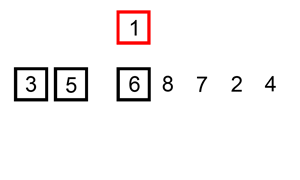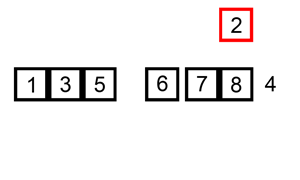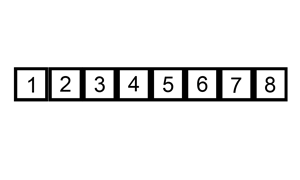
插入排序不适合对于数据量比较大的排序应用。但是,如果需要排序的数据量很小,比如量级小于千,那么插入排序还是一个不错的选择。 插入排序在工业级库中也有着广泛的应用,在STL的sort算法和stdlib的qsort算法(???)中,都将插入排序作为快速排序的补充,用于少量元素的排序(通常为8个或以下)。
插入排序的改进:二分插入排序
对于插入排序,如果比较操作的代价比交换操作大的话,可以采用二分查找法来减少比较操作的数目,我们称为二分插入排序。
代码如下:
当n较大时,二分插入排序的比较次数比直接插入排序的最差情况好得多,但比直接插入排序的最好情况要差,所当以元素初始序列已经接近升序时,直接插入排序比二分插入排序比较次数少。二分插入排序元素移动次数与直接插入排序相同,依赖于元素初始序列。
插入排序的更高效改进:希尔排序
希尔排序,也叫递减增量排序,是插入排序的一种更高效的改进版本。希尔排序是不稳定的排序算法。
希尔排序是基于插入排序的以下两点性质而提出改进方法的:
- 插入排序在对几乎已经排好序的数据操作时,效率高,即可以达到线性排序的效率
- 但插入排序一般来说是低效的,因为插入排序每次只能将数据移动一位
该方法的基本思想是:先将整个待排元素序列分割成若干个子序列(由相隔某个“增量”的元素组成的)分别进行直接插入排序,然后依次缩减增量再进行排序,待整个序列中的元素基本有序(增量足够小)时,再对全体元素进行一次直接插入排序。因为直接插入排序在元素基本有序的情况下(接近最好情况),效率是很高的,因此希尔排序在时间效率上比前两种方法有较大提高。
以n=10的一个数组(49, 38, 65, 97, 26, 13, 27, 49, 55, 4)为例:
第一次 gap=10/2=5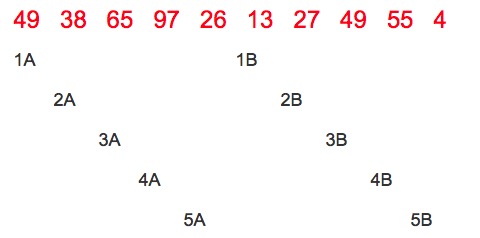
第二次 gap=5/2=2 排序后: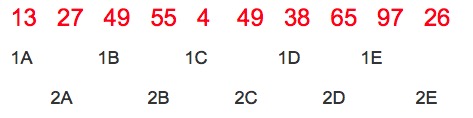
第三次 gap=2/2=1
第四次 gap=1/2=0 排序完成
希尔排序的代码如下:
|
|
很明显,上面的shellsort1代码虽然对直观的理解希尔排序有帮助,但代码量太大了,不够简洁清晰。因此进行下改进和优化,以第二次排序为例,原来是每次从1A到1E,从2A到2E,可以改成从1B开始,先和1A比较,然后取2B与2A比较,再取1C与前面自己组内的数据比较…….。这种每次从数组第gap个元素开始,每个元素与自己组内的数据进行直接插入排序显然也是正确的。
这样代码就变得很简洁了。
此处引用了CSDN博客:白话经典算法系列之三 希尔排序的实现。
事实上在我们使用的时候步长(gap)是有多种选择的,也可以有另外的更高效的步长选择。
归并排序
归并排序是创建在归并操作上的一种有效的排序算法,效率为O(nlogn),1945年由冯·诺伊曼首次提出。
归并排序的实现分为递归实现与非递归(迭代)实现。递归实现的归并排序是算法设计中分治策略的典型应用,我们将一个大问题分割成小问题分别解决,然后用所有小问题的答案来解决整个大问题。非递归(迭代)实现的归并排序首先进行是两两归并,然后四四归并,然后是八八归并,一直下去直到归并了整个数组。
归并排序算法主要依赖归并(Merge)操作。归并操作指的是将两个已经排序的序列合并成一个序列的操作,归并操作步骤如下:
|
|
首先考虑下如何将二个有序数列合并。这个非常简单,只要从比较二个数列的第一个数,谁小就先取谁,取了后就在对应数列中删除这个数。然后再进行比较,如果有数列为空,那直接将另一个数列的数据依次取出即可。
解决了合并有序数列问题,再来看归并排序,其的基本思路就是将数组分成二组A,B,如果这二组组内的数据都是有序的,就可以很方便的将这二组数据进行排序。那么如何让这二组组内数据有序呢?
可以将A,B组各自再分成二组。依次类推,当分出来的小组只有一个数据时,可以认为这个小组组内已经达到了有序,然后再合并相邻的二个小组就可以了。这样通过先递归的分解数列,再合并数列就完成了归并排序。
|
|
图解: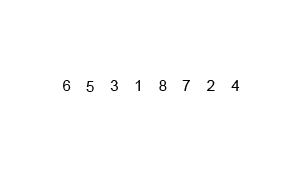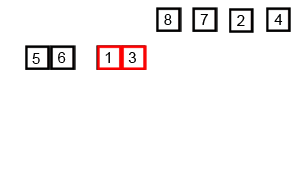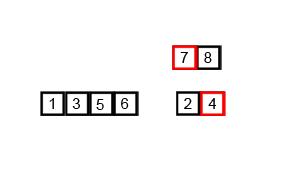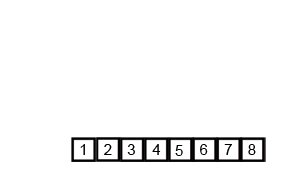
堆排序
呸,看不懂,等老夫解决数据结构之后来干你!
快速排序
你也给我等着…